
数量化2類の基本
数量化2類で明らかにできること
数量化2類は判別分析と非常によく似た手法です。目的変数のデータ形態は判別分析と同じカテゴリーデータです。
説明変数のデータ形態は、判別分析が数量データであるのに対し、数量化2類はカテゴリーデータです。
数量化2類は、目的変数と説明変数との関係を調べて関係式を作成し、その関係式を用いて次のことを明らかにする手法です。
① 説明変数カテゴリーと目的変数カテゴリーとの関連性
② 説明変数の重要度ランキング
③ 判別(予測)
数量化2類で適用できるテーマ
数量化2類が適用できるテーマを示します。
新規開店するお店の前を通行する人を対象に来店意向のアンケートを行いました。来店意向が「有る」と「無い」を回答した25人のデータから、来店有無判別の関係式を作成し、来店意向が「わからない」と回答した5人について来店有無を判別(予測)します。
このとき収集したデータの形態を調べると、年齢、性別、酒嗜好度は説明変数でカテゴリーデータ、来店意向有無は目的変数でカテゴリーデータです。これよりこのテーマには数量化2類が適用されることになります。
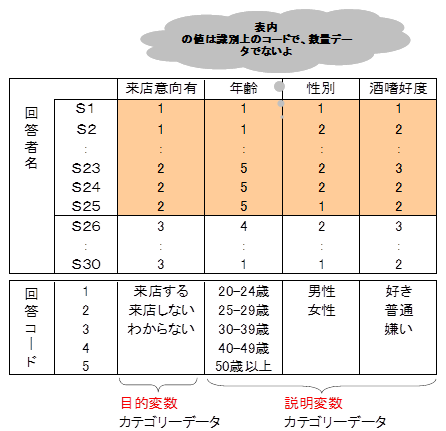
数量化2類で適用できるデータ
右の数表はテーマのデータを示したものです。
数量化2類に適用するデータは次式の条件を満たしてなければなりません。
個体数>説明変数カテゴリー総数-説明変数個数+1
右のデータは、
説明変数カテゴリー総数=5(年齢)+2(性別)+ 3(酒嗜好度)=10
説明変数個数 =3
説明変数カテゴリー総数-説明変数個数+1 = 10-3+1=8
関係式を作成するために数量化2類を適用する個体数は25人なので、
25>8より、このデータは数量化2類が適用できます。
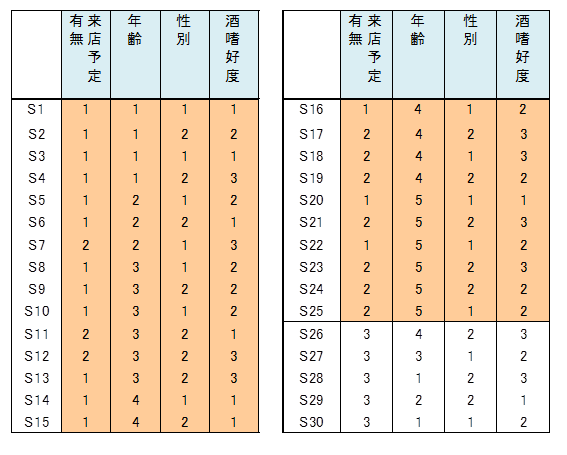
数量化2類をする前の基本解析
数量化2類を行う前に基本解析を行います。
目的変数、説明変数はカテゴリーデータなので、各カテゴリーの割合を算出します。
目的変数と説明変数の関係を調べます。
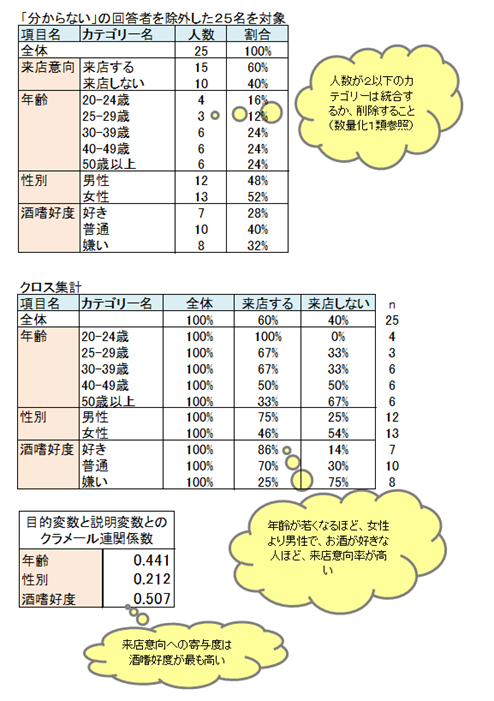
目的変数がカテゴリーデータ、説明変数がカテゴリーデータなので、クロス集計とクラメール連関係数を算出します。クロス集計、クラメール連関係数から目的変数と関連している説明変数は何かを検討します。
カテゴリースコア
クロス集計から、年齢が若くなるほど、女性より男性で、お酒が好きな人ほど来店意向率が高くなることがわかりました。
残念ながら、この情報だけでは予測の問題は解決できません。そこで、クロス集計から把握できたこと、すなわち各カテゴリーの回答者が来店意向の「有り」「無し」のどちらに近いかを、何らかの方法を用いて数量で表現することを考えてみます。
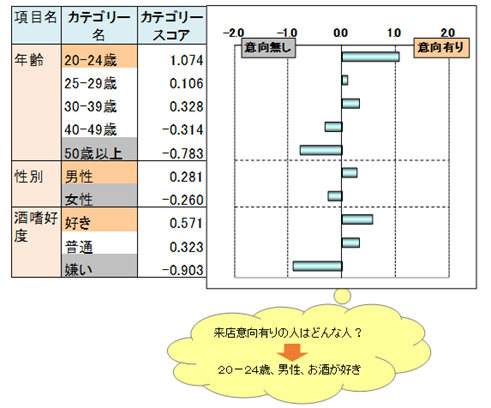
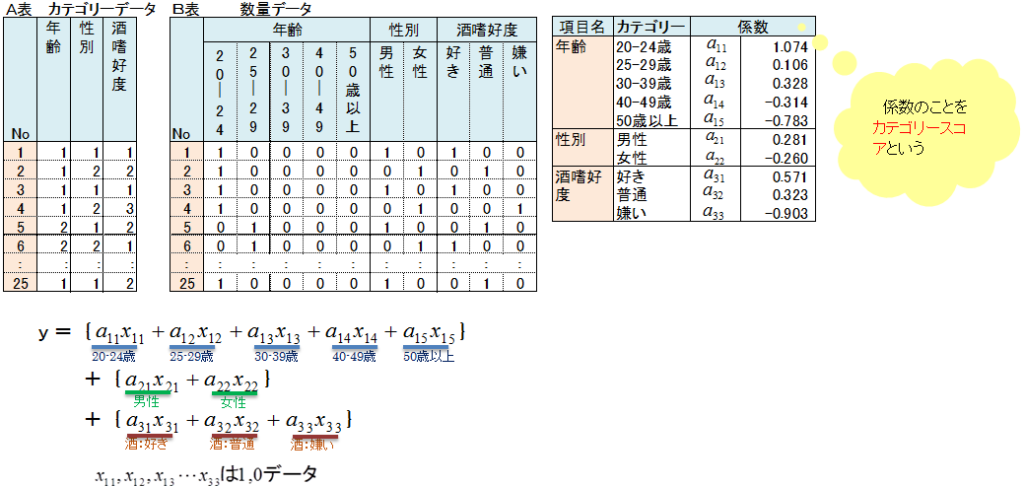
具体的には、「20-24歳」の数量は1.1点、「50歳以上」は-0.8点で、「20-24歳」は来店意向の「有り」に近く、「50歳以上」は「無し」に近いといったことがわかる、各カテゴリーの数量化です。
仮にすべてのカテゴリーに数量が与えられたとすれば、予測したい人、例えばテーマのS30は「20-24歳」「男性」「酒嫌い」で、与えられたそれぞれの数量の合計によって、S30は「有り」「無し」のどちらに近いかを予測することができます。
このような考え方で各カテゴリーの数量化を行う方法が、数量化2類という解析手法です。数量化された値のことを、数量化2類ではカテゴリースコアといいます。
数量化1類のカテゴリースコアは、説明変数各カテゴリーの目的変数に対する貢献度が把握できます。
例えば、「巨人が勝つ」のスポーツ新聞売上部数の貢献度はプラス8部です。
これに対し、数量化2類のカゴリースコアは、説明変数各カテゴリーの目的変数カテゴリーへの近さ(関連性)が把握できます。
来店予定有無のデータに数量化2類を適用し、カテゴリースコアを求めると、次の表のようになります。
カテゴリースコアは関係式の係数
A表はカテゴリーデータです。
B表はカテゴリーデータを1,0の数量データに変換したものです。
関係式はB表のデータに対するものです。関係式の係数はカテゴリースコアです。
サンプルスコア
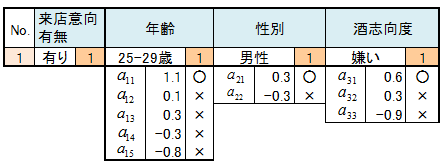
S1の人のデータを関係式に代入してYを求めます。求められたYをサンプルスコアといいます。全ての人についてサンプルスコアを求めます。
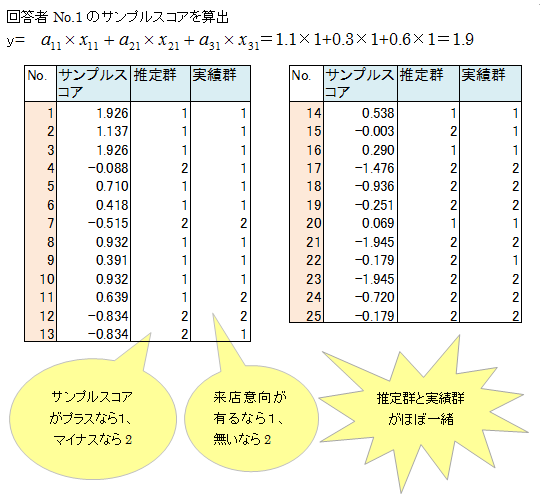
サンプルスコアの値が大きい人ほど来店意向度が高い人といえます。値がプラスの人を来店意向層、マイナスの人を来店未意向層と名称します。下記表の推定群で、来店意向層を1、来店未予定層を2として記載しました。
実績群は来店意向の回答データです。推定群と実績群はほぼ一致しています。言いかえれば、カテゴリースコアは推定群と実績ができるだけ一致すように求められたものです。
分析精度
分析精度を調べる方法を二つ示します。
一つは、実績値(来店意向有無)とサンプルスコアとの相関比です。相関比の値が大きいほど分析精度は高く、基準の0.5を上回れば関係式は予測に使えると判断します。
相関比はいくつ以上あれば良いかと、よく質問されます。残念ながらいくつ以上あれば良いという統計学的基準はありません。この基準は、分析者が経験的な判断から決めることになります。先生は、右の表のように決めていますが、皆さんはいかがでしょうか。
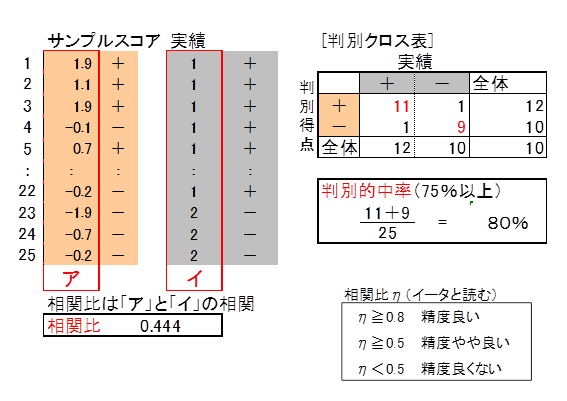
もう一つは、判別クロス表を用いる方法です。判別クロス表は、サンプルスコアの符号「+、-」と来店意向有無とをクロス集計したものです。判別クロス集計表の赤表示の数値は実績値とサンプルスコアの符号が一致した人数を示しています。一致人数の全人数に占める割合を判別的中率といいます。判別的中率の値が大きいほど分析精度は高く、基準の75%を上回れば関係式は予測に使えると判断します。
判別的中率、相関比両方が基準の値を上回るのが理想です。しかしこの例題のように片方だけが基準を下回っても関係式を適用する場合、予測の精度がやや劣ることを認識してください。
説明変数の目的変数に対する重要度
来店意向の例題の説明変数の項目数とカテゴリー数を再確認します。項目数は3つ、カテゴリー数は10です。
10個のカテゴリーの目的変数のカテゴリーへの近さ(関連性)は、カテゴリースコアで把握できました。
3個の項目の目的変数に対する重要度ランキングは、数量化1類で学んだレンジ、寄与率で把握できます。
レンジは当該項目のカテゴリースコアの最大値と最小値との差によって求められます。年齢は20-24歳のカテゴリースコアが1.1で最大、50歳以上が-0.8で最小、したがってレンジは1.1-(-0.8)=1.9となります。
各項目のレンジのレンジ合計に占める割合を寄与率といいます。レンジ、寄与率が大きい項目ほど、目的変数への影響度が大きい、重要な項目だといえます。
全ての項目についてレンジ、寄与率を求め、右記に示しました。
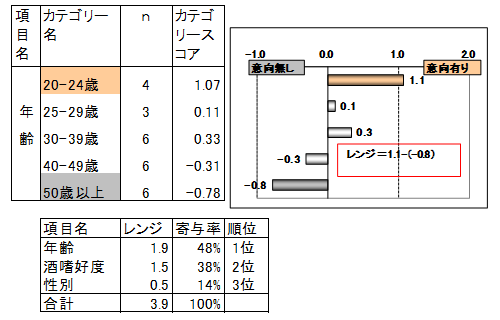
来店意向有無には年齢が最も影響し、次に酒嗜好度、性別が続きます。
年齢が高くなるほどカテゴリースコアが大きくなる傾向の中で、25-29歳のカテゴリースコアは傾向から外れています。この結果は、25-29歳の意向度が30-39歳の意向度に比べ低い事実なのか、25-29歳のn数が少ないことにより起こる現象か迷います。
このような悩みを解消するためには、各カテゴリーのn数を多くすることです。
注.数学的な意味合いで確保したいn数は3以上です。